|
本日金价,一克1000.06元;95号汽油,每升8块5毛7;电费是门路计价,家庭用电最多每千瓦时8毛9;…… 克、升、千瓦时——单元一朝笃定,便不错被标注价钱,而价钱决定了消费,也潜移暗化地塑造着每个东说念主的生存。大多量时候,咱们并不热心这些单元自身,只消它们饱和清爽,清爽到不错比拟、不错结算,它们就会肃静荫藏我方,了债到缴费单和购物小票背后。 但当今,一种全新的、目生的计量单元,正浮出水面,走入更多东说念主的生存。 它叫Token。 淌若你最近玩过、神话过,甚而我方试着调用过各式AI助手或“智能体”(比如近期流行起来的Openclaw“小龙虾”),那么你应该依然和它打过照面了。你与AI的每一次对话,岂论是让它回答一个问题、写一封邮件,如故归来一篇论文,后台阿谁肃静进步的计价数字,单元便是Token。 Token,便是AI寰宇的“克”“升”和“千瓦时”。
Token到底在计量什么? 在OpenAI的官方页面上,用一句话简便地详尽了Token:Token是天然谈话的数学暗示。 在汉文里,Token常被翻译为“词元”,你不错将它联贯成为大模子用来处理天然谈话的基本单元,或大模子处理信息的最小信息单元。一段话、一个问题在参预AI模子被计议机处理前,最初要被“分词器(Tokenizer)”拆分红一个个Token。 一个Token可能是一个标点、一个汉字、一个英文单词,或者一个常见的词组——这取决于不同AI模子分词器的联想。比如“一又友买了西瓜手机!”可能被拆为“一又友”“买”“了”“西瓜”“手机”“!”,“Transformer”可能被拆成“Trans”“former”。 这些被拆分好的Token,对于你我来说是有真义的笔墨,但对于大模子而言,它并不料识,更不睬解。为了让AI“联贯”,大模子会先给每个Token分派一个数字编号,然后将这个编号转机为一组数字坐标(向量)。这个坐标决定了AI怎样“联贯”这个词。 更短处的是,AI理罢黜何一个词,皆要看它和其他词的联系。比如“西瓜”这个词,AI在熟习中既见过它和“手机”“汽车”“公司”“发布会”一说念出现,也见过它和“吃”“食品”“厚味”一说念出现。当AI看到“西瓜手机”这个组合时,它判辨过“汽车”这个词的坐标,来退换“西瓜”在面前这句话里的含义——让它的坐标更接近“品牌”,隔离“食品”。 AI的整个这个词“想考”历程,便是计议一整句话里整个Token坐标之间的复杂联系。它不会死记硬背“小米=品牌”或“小米=食品”,而是凭据高下文动态计议。
图源:用AI生成的 聊到这里,你还会以为,Token的忽地便是你输入和输出的字数简便相加吗?接下来,咱们通过一次无为对话,望望Token到底是怎样被忽地掉的。 咱们让AI写一封信给十年后的我方:
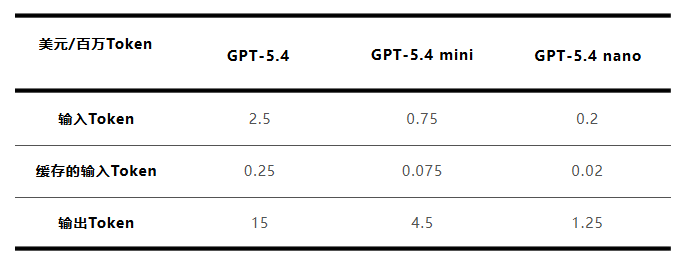
图片开头:我方截取的 教导输入十几个字,AI恢复四五百字,看起来不外几百个Token,但事实上忽地的Token远不啻屏幕上那几行字: 系统预设教导(System Prompt):在你启齿之前,AI依然被输入了一段看不见的教导,被用来端正和你聊天的AI的身份,口吻,恢复用词特征和安全范畴。许多东说念主会嗅觉不同公司的AI居品有不同的脾气特征,机密就在这里。这段教导不会线路在对话中,关联词也参与了模子的计议,会忽地掉一部分Token。 对话的历史高下文(Context):淌若你不是第一次发问,模子频频就需要探讨之前的高下文信息,智力知说念整个这个词对话在聊什么,保证对话的连气儿性。是以之前的发问与它之前的回答,皆会参预最新这轮对话的计议。也便是说,对话越长,对话的轮次越多,最新的单轮苦求忽地的Token也就越多。 想考历程(Reasoning):这是更避讳的忽地,许多具备深度推理模式的模子,在回答之前,它会进行一轮里面计议去比拟推演不同的回答,最终将它觉得最优的回答呈现出来。这些不展示出来的“想考设施”,澳洲幸运8app相似忽地资源。 总之,Token计量的,并不仅仅你看到AI模子给出的谜底,而是生成这个谜底所需的全部计议资源。而参预以Openclaw为代表的agent场景,这种Token的忽地会被指数级扩大。 比如让一只小龙虾替你干活,把“帮我整理一下文献夹”这句话甩给它之后,它可能需要先读懂这个条目,然后拆解成十几个子任务,每个子任务区别调用一次AI,每次调用皆带着完整的系统教导和高下文,必要的时候还要反复查验有莫得作念对,是否需要修正。 这背后可能是几十轮对话、几万个Token的连锁忽地,这亦然它看起来只干了点无为的活,但却特地忽地 Token 的原因。 为什么“输出Token”,比“输入Token”贵6倍? 对于Token的价钱,许多东说念主可能没什么感知,毕竟岂论和哪个AI聊天,对话Token的忽地皆打包在了免费额度或者订阅制里,很难平直感受到。 咱们以OpenAI为例,来辩论一下它的价钱表:
图源:我方作念的 不错看出,模子越宽阔,Token越贵,从Nano到法度版,每百万Token价钱差距高达十倍。这很容易联贯:参数限度越大、模子智商越强,越能科罚越复杂问题的模子,Token的价钱天然越贵。 而对比起不同公司,同为面前顶级的AI模子,每百万TokenGPT-5.4的报价是15好意思元,Claude Opus4.6是25好意思元,Gemini 3.1 Pro的报价则凭据prompt长度不同列出了12好意思元和18好意思元两个价钱。差距依然存在,这里的订价计策就比拟复杂了,公司的定位与交易模式,模子的资本、受众、智商皆会有所影响。 这些真义皆很容易联贯,但信得过的谜题还不是这个。仔细望望,并吞个模子的“输入Token”和“输出Token”尽然也存在6倍的订价差距,乐鱼这是何如回事? 输入(prefill)的时候,AI要联贯你的全部问题,每个词皆要和其他整个词作念筹商计议(即“自防卫力机制”,计议量会跟着文本长度的增多急剧增长);而输出(decode)时,模子依然将输入的内容分析计议竣事,只需要把拒绝一个字一个字“吐”出来即可,似乎应该更舒缓才对。 其实,谜底并不在计议量,而在计议效劳上。 处理输入时,整个的Token皆是同期送入处理器的,千千万万个计议中枢并走时行,这是大限度的矩阵乘矩阵运算,GPU底本便是为了这种大限度并行计议而联想的。是以在应答这类任务时,计议效劳极高,甚而不错说在允许范围内,Token输入越长,越容易让GPU的计议中枢接近满载职责情景。 但输出的时候,情况截然有异了。模子必须一个Token一个Token生成回答,每一个皆需要依赖上一个生成的拒绝,无法并行伸开。每次生成,模子皆需要从显存中读取一次参数,同期合资依然生成的高下文进行计议,全体更接近矩阵乘向量的运算。 这个历程的瓶颈取决于内存带宽,也便是说,GPU绝大多量时间莫得在计议,而是在恭候数据从显存被传过来,信得过作念计议的时间占比仅有1%~5%,计议效劳骤降。 用更准确的话说,处理输入是计议密集型(compute-intensive)职责,GPU在作念它最擅长的事,生成输出是内存带宽密集型(memory-bound)职责,GPU的计议中枢大部分时间在空转等数据。 是以,输出Token的奥秘价钱,内容上是在为一块每小时房钱几好意思元的芯片,以不到百分之一的效劳运转而被动恭候的时长付费。 这也便是为什么即使是并吞种模子,输出Token的价钱会比输入Token贵那么多,这是算力和内存带宽之间树大根深的分歧称不匹配。
图源:nvidia GPU的计议智商在赶紧增长,关联词显存的传输速率却跟不上,这种矛盾由来已久。它源于冯·诺依曼架构入彀算与存储分离带来的瓶颈问题,而果真整个当代计议机皆没能透彻绕开它。 算力每一代翻倍,内存带宽的进步速率大致只消它的一半,这意味着每一代新芯片出来,处理输入会变得更快更低廉,但生成输出的改善幅度要小得多。 业界天然有在试图缓解这个问题。举例投契采样(Speculative Decoding)让一个小模子先快速猜出几个词,再让大模子一次性考证,把串行计议的一部分形成并行计议。又或者MoE架构让每个Token只激活一小部分参数,减少每次需要搬运的数据量。 这些本事皆在缓解症状,但莫得一种能根治病因,只消计议和存储如故物理上分开的两个东西,数据搬运的瓶颈就会一直存在。这也便是为什么Groq、Cerebras、Etched这些推理芯片创业公司,内容上皆在赌我方能绕开这个七十多年前的联想遗产。 Token价钱到底由什么决定?为什么近几年一直暴跌? 在聊这个问题之前,咱们要先理明晰Token的资本由什么决定。 咱们不错用一个简便的想路来分析,以面前数据中心主流使用的Nvidia H100为例,云租借的价钱大致在每小时2.5~3.5好意思元之间。这笔钱里,电费的花销占10%~20%,水冷、收集、运维这些加在一说念也莫得若干,大头如故在芯片自身的采购资本、硬件折旧以及干事商的利润上。 一度电能产出若干Token,和电自身的联系不大,主要取决于这度电供给了什么芯片、跑的是什么架构、优化作念到了什么进度。相似一度电,喂给一块在处理输入时满载运行的GPU,和一块在生成输出时空转百分之九十九的GPU,处理的Token数就不错差出数目级。 是以当咱们问“Token的价钱由什么决定”时,最准确的回答是:由一块芯片在单元时间内能处理若干Token决定。 问题来了:既然Token的价钱不是被某一个身分单独决定的,而是由芯片物理结构、动力资本、模子架构甚而是市集竞争共同作用的拒绝。那它的价钱按说应该相对清爽,毕竟电费不会一年跌十倍,芯片也不会每个季度降价一半。 那么,为什么这几年Token的价钱在暴跌? 2023年头,要达到GPT-4水平的性能,每百万Token大致要20好意思元。到2026年,同等性能依然降到了0.4好意思元隔邻,五十倍的差距是何如来的? 这并非来自某一项本事的冲突,而是几个身分在同期影响,其影响拒绝是以乘法体现的。 最初是硬件在更新换代,GPU更快更低廉了,H100的云租借价钱也从2023年峰值的接近8好意思元/小时降到了2.5~3.5好意思元。 然后是软件的优化,连气儿批处理和PagedAttention这类阅兵,提高了KV cache的诈欺率和并发智商,在安妥的负载下,抵赖普及可达数倍。 接下来,模子架构也在变智慧,羼杂内行架构(MoE)让模子无须为处理每个Token动用整个参数,这一项又能将推理资本显赫裁减。 单独每一项看皆不算太惊东说念主,乘起来成果就很赫然,硬件一层、系和解层、架构一层,再加上开源带来的价钱竞争,推理资本就被一层层压了下去。 同期,模子自身在用更少的参数作念到更多的事。往时的模子频频依赖不断扩大参数限度来普及智商,但近两年,更多量据、更好的熟习要领以及更熟习的架构联想,使得较小限度的模子也能靠拢甚而在部分任务上荒芜上一代更大的模子。 这意味着,相似的智商不再需要相似限度的计议资源。模子变小,带来的不仅是显存占用下跌,更短处的是每一步推理所需的数据搬运和计议支拨皆随之裁减了。 是以Token低廉了。 低廉了若干? 大约不错拿咱们更熟悉的手机流量来对比。从2014年到当今,中国的手机流量价钱降了几十倍甚而几百倍。诚然民众的话费账单差距不大,但流量低廉后催生的各色使用神情,收集应用、短视频、手机游戏,依然绝对改换了咱们的生存。 尽管Token并不算一个好意思满的计量单元,价钱细节繁复,变化太多,大多量用户对它无比目生,但它也应该也会和流量走上并吞条路,可能速率更快,可能带来的变化更大。 克、升、千瓦时,从当今驱动乐鱼,你大约需要多意识一个计量单元——Token。 真钱三公棋牌游戏官方网站 |





 备案号:
备案号: